ThumbGate
<p align="center"> <a href="https://thumbgate.ai"> <img src="public/assets/brand/thumbgate-icon-512.png" alt="ThumbGate" width="128" height="128" /> </a> </p>AI coding agents repeat mistakes — and one wrong tool call can wipe a directory, leak a key, or push broken code.
ThumbGate is the local-first firewall for AI coding agents. It runs in the PreToolUse hook on your machine and blocks dangerous tool calls — rm -rf, secret exfiltration, off-scope edits, a bad git push — before they execute, across Claude Code, Cursor, Codex, Gemini, Amp, Cline, and OpenCode. No server, no gateway. (Regulated-industry policy templates — legal intake, financial compliance, healthcare — build on the same engine.)
The product is a self-improving enforcement layer: thumbs-down feedback, prompt evaluation, and proof from prior runs become prevention rules that permanently stop repeated failures before the next tool call.
<p align="center"> <img src="docs/media/thumbgate-demo.gif" alt="ThumbGate blocking an AI agent's dangerous commands (rm -rf, force-push, chmod 777) in real time, while letting safe commands through" width="820" /> </p> Agent tries: rm -rf tests/
ThumbGate: ⛔ BLOCKED — "Never delete test directories"
Pattern matched: rm.*-rf.*tests
Source: your thumbs-down from last Tuesday
Tokens spent on this repeat: 0npx thumbgate init # auto-detects your agent, wires hooks, 30 secondsWorks with Claude Code, Cursor, Codex, Gemini CLI, Amp, Cline, OpenCode and any MCP-compatible agent. Free tier: 2 feedback captures/day (10 total) and up to 3 active auto-promoted prevention rules. Pro: $19/mo or $149/yr — unlimited rules, history-aware lessons, feedback sessions, dashboard, DPO export. Enterprise (custom pricing, scoped after intake) adds a shared hosted lesson DB, org dashboard, and shared org-wide enforcement.
![]()

![]()
"A better dashboard doesn't make the agents more reliable. The hard part isn't visibility. It's trust."
— Rob May, CEO & co-founder, Neurometric AI, quoted in The New Stack on Anthropic's Claude Code Agent View (May 2026).
ThumbGate is the open-source layer that makes the trust part real: PreToolUse gates, thumbs-down to rule, audit trail on every interception.
Agentic development cycle fit
Agentic development is becoming a loop: Guide → Generate → Verify → Solve. ThumbGate gives that loop a hard execution boundary.
- Guide: standards, prior thumbs-downs, and approval policies become concrete context.
- Generate: Claude Code, Cursor, Codex, Gemini, Amp, Cline, OpenCode, and MCP agents keep producing plans and tool calls.
- Verify: risky actions need evidence before execution, not just after PR review.
- Solve: blocked failures become reusable lessons, shared prevention rules, DPO exports, and audit events.
In that stack, ThumbGate is the pre-action gate between generated intent and executed action.
Discoverable slash-commands — the guardrail layer for spec-driven agents
Spec-driven agent frameworks like GSD (get-shit-done) and GitHub Spec Kit are great at planning and generating work — they expose dozens of discoverable /gsd-* / /specify commands in the agent command palette. ThumbGate is the guardrail layer for spec-driven agents: it sits after the plan, on the boundary between a generated tool call and its execution. It works alongside GSD / Spec-Kit, not instead of them — they decide what to build; ThumbGate enforces what the agent must never do while building it.
npx thumbgate init installs these commands into your agent's palette (.claude/commands/, .gemini/commands/, .antigravitycli/commands/) so the enforcement layer is as browsable as the planning layer:
| Command | What it does | Wraps (existing capability) |
|---|---|---|
/thumbgate-guard | Turn the last agent mistake into a hard prevention rule | capture_feedback + thumbgate force-gate |
/thumbgate-rules | List the active prevention rules + lessons guarding this repo | prevention_rules, get_reliability_rules, search_lessons |
/thumbgate-blocked | Show what's actually been blocked — gate stats + enforcement matrix | gate_stats, enforcement_matrix |
/thumbgate-protect | Show branch/release governance; grant a scoped, expiring approval | get_branch_governance, approve_protected_action |
/thumbgate-doctor | Health-check the wiring (hooks, MCP, agent-readiness) | thumbgate doctor |
Each is a thin wrapper over an existing MCP tool or CLI command — no new enforcement logic, just discoverability.
🎬 90-second demo
Watch the force-push scenario: agent tries to git push --force, one thumbs-down, next session it's blocked — zero tokens spent on the repeat.
▶ Watch the 90-second demo · Script · ElevenLabs narration: npm run demo:voiceover
First-dollar activation path
If someone is not already bought into ThumbGate, do not lead with architecture. Lead with one repeated mistake.
- Show the pain: open the ThumbGate GPT and paste the bad answer, risky command, deploy, PR action, or agent plan before it runs again.
- Capture the lesson: type
thumbs down:orthumbs up:with one concrete sentence. Native ChatGPT rating buttons are not the ThumbGate capture path; typed feedback is. - Enforce the repeat: run
npx thumbgate initwhere the agent executes so the lesson can become one of your Pre-Action Checks instead of another reminder. - Upgrade only after proof: Solo Pro is for the dashboard, DPO export, proof-ready evidence, and higher capture limits after one real blocked repeat. Team starts with the Workflow Hardening Sprint around one repeated failure, one owner, and one proof review.
The buying question is simple: what repeated AI mistake would be worth blocking before the next tool call?
The Problem — the bill nobody talks about
Frontier-model calls are not cheap. Sonnet 4.5 is ~$3 / 1M input tokens and ~$15 / 1M output tokens. Opus is 5× that. Every time your agent:
- hallucinates a function name and you have to correct it,
- retries the same failing tool call until it gives up,
- regenerates a 4,000-token plan you already approved last session,
- repeats a destructive command you blocked manually yesterday,
…you are paying for that round-trip. Twice if it retries. Three times if you re-prompt. And the agent has no memory across sessions, so the meter resets every Monday.
Session 1: Agent force-pushes to main. You fix it. +4,200 tokens
Session 2: Agent force-pushes again. You fix it. +4,200 tokens
Session 3: Same mistake. Again. You lose 45m. +5,800 tokensThat's ~$0.21 in tokens just to fix the same mistake three times — multiplied by every developer, every repeated-mistake class, every week. The math gets ugly fast.
The Solution — fix it once, the bill never sees it again
Session 1: Agent force-pushes to main. You 👎 it. +4,200 tokens
Session 2: ⛔ Check blocks the force-push. Zero round-trip. +0 tokens
Session 3+: Never happens again. +0 tokensOne thumbs-down. The PreToolUse hook intercepts the call before it reaches the model — no input tokens, no output tokens, no retry loop. The dashboard tracks tokens saved this week as a live counter so you can see exactly what your prevention rules are worth. Mark a review checkpoint once, and the dashboard narrows the next pass to only the feedback, lessons, and check blocks that landed since your last review.
ThumbGate doesn't make your agent smarter. It makes your agent cheaper to be wrong with.
🧠 The Context Brain
Every coding agent starts each session amnesiac — it has no memory of the mistakes it made yesterday, the fixes your team already rejected, or the rules this repo enforces. So it repeats them, and you pay for it again.
ThumbGate gives your repo a context brain: a single, versioned, agent-readable artifact that consolidates everything the agent should know before it acts — the lessons it has learned, the guardrails it must not cross, the gates that are enforced, and the project's own instruction files.
npx thumbgate brain --write # → .thumbgate/BRAIN.mdThen point your agent at it — add Read .thumbgate/BRAIN.md first to your CLAUDE.md / AGENTS.md, and every Claude Code, Codex, Cursor, or Gemini CLI session boots with your repo's institutional memory already loaded. The output is deterministic, so BRAIN.md lives in git and only changes when the underlying memory does — review it like any other file.
# ThumbGate Context Brain
## What this codebase taught its agents (lessons)
- ⛔ Force-pushing to main was rejected — use --force-with-lease on feature branches only
## Guardrails — do NOT repeat these (prevention rules)
- Never run DROP on production tables
## Active enforcement (gates)
- `DROP.*production` → blockSame idea the SEO world is now calling a "client brain" — persistent context that AI reads before doing the work — applied to engineering: the institutional memory that stops your coding agent from relearning the same lesson on your dime.
Quick Start
npx thumbgate init # auto-detects your agent, wires everything
npx thumbgate capture down "Never run DROP on production tables"That single command creates a prevention rule. Next time any AI agent tries to run DROP on production:
⛔ Check blocked: "Never run DROP on production tables"
Pattern: DROP.*production
Verdict: BLOCKArchitecture
ThumbGate operates as a 4-layer enforcement stack between your AI agent and your codebase:
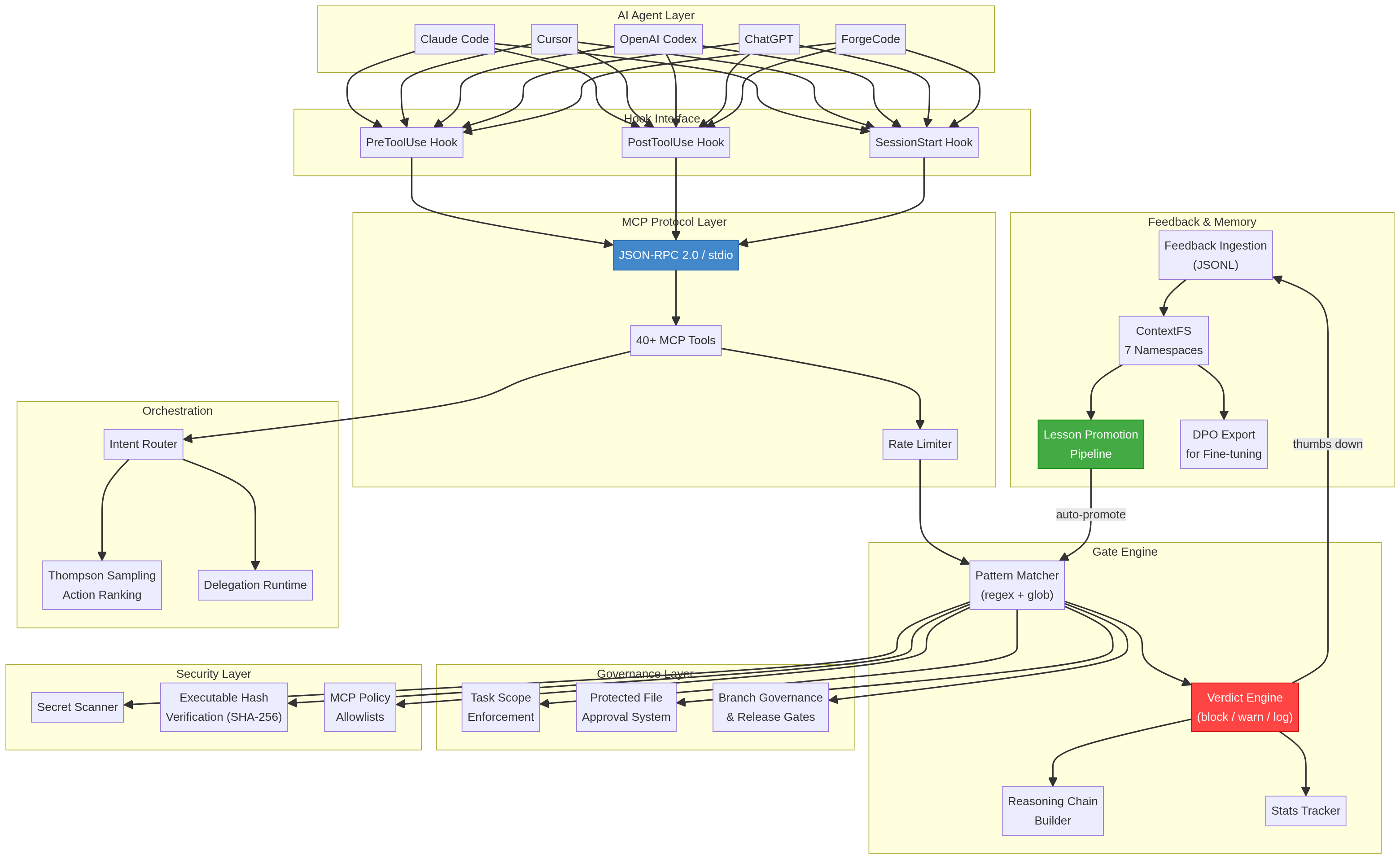
Layer 1: Feedback Capture
Your thumbs-up/down reactions are captured via MCP protocol, CLI, or the ChatGPT GPT surface. Each reaction is stored as a structured lesson with context, timestamp, and severity.
Layer 2: Check Engine
The check engine converts lessons into enforceable rules. The runtime gate decision is deterministic — literal pattern match → AST match → scoped rule lookup. No LLM call on the enforcement path.
Where retrieval is needed (an agent is about to run a destructive command not on the literal block list, but semantically similar to one we've blocked before), ThumbGate uses local CPU-only bge-small embeddings via LanceDB's built-in pipeline. No external API call, no inference cost beyond CPU. So "no LLM in enforcement" holds: the gate decision uses no LLM; the rule corpus is just searchable via local embeddings.
Thompson Sampling tunes per-rule confidence weights for soft-gating rules so high-noise rules quiet down and high-signal rules sharpen. It never decides whether a rule fires — a hard rule like "block `git push --fo
…